目录
原来的方案
可以参考这篇文章,《B君笔记SEO 方案自爆》。
总结成2点
- 前端用vue,route 模式选择hash
- seo 主要由后端 ForSpider 模块负责。
route hash 方案和 mavonEditor 目录跳转不兼容
mavonEditor 目录
mavonEditor 自动生成的格式是:#字母_编号
https://bjun.tech/blog/xphp/51#_4
e.replace(/[^\w\s]/gi, "").split(" ").join("_")
原理就是利用锚点跳到设定的文章位置。
了。
<a href="#_1">点我</a>
<h1 id="#_1">到这里</h1>
锚点特别之处
- 不会触发导航守卫(Navigation Guards)
所以通过导航守卫修改地址想法泡汤
- 可以监听点击事件,阻止默认事件
route hash
情况
| 旧版route hash |
出现的情况 |
| 原本的路径 |
https://bjun.tech/#/blog/xphp/51 |
| 点击标题 “#_4” 变成 |
https://bjun.tech/#_4 |
| 结果 |
跳转到对应标题 |
问题
- 不能刷新,一刷新 hash=#_4,明细错误路径。
- 不能复制链接转发,同样hash=#_4,错误路径,无法打开原文。
- 基于2,更不可能直接跳转到对应标题
- 站内链接都不能使用标题跳转
其中第四点实我最不能忍的,记笔记写东西引用旧文章很正常,不能跳转到标题只能跳转到章节很不爽
我做了一点尝试
- 尝试修改mavonEditor源码,自动生成时自动加上页面基础前缀。这个思路应该时ok的,不过有点复杂,放弃。
- 监听点击事件,阻止默认事件
可以实现点击跳转,不修改地址。这里会出现一个问题,后退的时候会回到上一页,而不是上个位置。
a.addEventListener('click',function(a){
document.querySelector(e.getAttribute('href')).scrollIntoView(true)
a.preventDefault();
},false);
- 加载数据后重新生成目录的锚点和位置信息
这里还需再加载页面时分离出锚点位置,再手动跳转到位置。这里的坑更深,也放弃。
let id = that.$route.params.anchor
id && document.querySelector(id).scrollIntoView(true)
新方案 route 升级成 hisotry
路径格式
https://bjun.tech/blog/xphp/51#_4
加载完数据后跳转到指定位置
window.location.hash && document.querySelector(window.location.hash).scrollIntoView(true)
nginx 新增配置
生成环境
转发地址
location ~* ^\/(blog)\/? {
rewrite ^/(.*)$ /index.php last;
}
index.php 主要是加载了vue的html文件
<?php
include .'/index.html';
开发环境
http://127.0.0.4:8080 为 npm run serve 的监听地址和端口
publicPath 为 npm run serve 配置的 publicPath
location ~* ^\/(blog)\/? {
proxy_pass http://127.0.0.4:8080;
}
location ^~ /publicPath/ {
proxy_pass http://127.0.0.4:8080;
}
问题解决
hash 到 history 对seo影响
hash 模式
hash部分也就是 /#/blog/1 是不会提交到服务器,无论是第一次还是后续不刷新跳转。
正因为这个原因,如果是hash模式,是使用不了SSR方案的。
history 模式
history的path第一次进入是会提交到服务器的,这也是nginx路径可以进行重写的原因。
在php中 中可以通过$_SERVER[‘REQUEST_URI’]获取。
echo $_SERVER['REQUEST_URI'];
一样的地方
无论是hash或者history,都是异步加载的页面,像百度这类搜索引擎,只能爬到一推js.
Noscript 方案
灵感来自 如何让搜索引擎抓取AJAX内容?
思路
根据 $_SERVER[‘REQUEST_URI’]判断是否需要Noscript内容输出和解析出页面参数。
修改模板index.html
可以改的参数title,description,打印页面内容的noscript
<!DOCTYPE html>
<html lang="">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width,initial-scale=1.0">
<title>{% titile %}</title>
<meta name="description" content="{% description %}">
</head>
<body>
<div id="app"></div>
<noscript>
{% noscript %}
</noscript>
</body>
</html>
修改入口index.php
按自己定义的规则解析路径,获取页面内容,进行替换,以下为简化的代码
$title = 'title';
$description = 'description';
$noscript = 'noscript 内容';
$callback = function($content){
return strtr($content,['{% titile %}'=>$title,'{% description %}'=>$description,'{% noscript %}'=>$noscript]);
};
ob_start($callback);
include .'/index.html';
ob_end_flush();
随时反馈
该方案才更新上了不久,记2021年10月3日
- noscript 方案bing好像不行。在url检查时会提示没有h1,noscript 标签内的h1并不能被识别。
- google 也不行,因为google 爬虫是支持js的,noscript 等于没有。
- 这几天翻了google和bing的官方文档,他们还是建议动态渲染输出静态html。bing对严重依赖JavaScript网站的官方建议
- 10月6号又进行了一次修改
- 保留noscript,但只是给没开启js的情况使用。
- 针对spider UA直接输出html页面。又回到之前ForSpider的方案,不同是,由于路径改成history,爬虫搜录的路径和真实路径是一致的,不用在进行一次跳转。
- 悲剧的事情发生了,今天bing 突然收录了十几个链接,看快照是2号的版本,也就是 “在url检查时会提示没有h1”的版本,现在就头疼了,noscript 究竟有用么,还是说6号的调整使页面合格了才被收录,快照还没来得及更新?后面再观察观察。
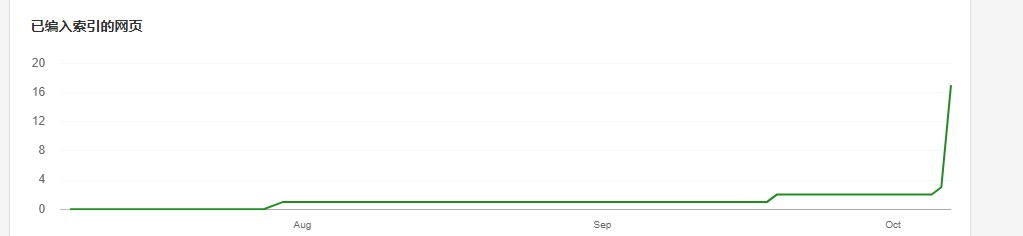
后续后变动再更新